
Imagine that you would like to communicate something about the size of an object, using as short a message as possible -- i.e., a single number. What would be a reasonable algorithm to employ? There's obviously no unique answer, and the "best" algorithm depends on the distribution of object types that you are trying to describe. Here's a decent algorithm:
Let rough size S = the radius of the smallest sphere within which the object will fit.
This algorithm allows a perfect reconstruction of the object if it is spherical, but isn't very satisfactory if the object is a javelin or bicycle wheel.
Nevertheless, it would be unreasonable to reject this definition as a single number characterization of object size, given no additional information about the distribution of object types.
I suggest we think about IQ in a similar way.
Q1: If you had to supply a single number meant to characterize the general cognitive ability of an individual, how would you go about determining that number?
I claim that the algorithm used to define IQ is roughly as defensible for characterizing cognitive ability as the quantity S, defined above, is for characterizing object size. The next question, which is an empirical one, is
Q2: Does the resulting quantity have any practical use?
In my opinion reasonable people should focus on the second question, that of practical utility, as it is rather obvious that there is no unique or perfect answer to the first question.
To define IQ, or the general factor g of cognitive ability, we first define some different tests of cognitive ability, i.e., which measure capabilities like memory, verbal ability, spatial ability, pattern recognition, etc. Of course this set of tests is somewhat arbitrary, just as the primitive concept "size of an object" is somewhat arbitrary (is a needle "bigger" than a thimble?). Let's suppose we decide on N different kinds of tests. An individual's score on this battery of tests is an N-vector. Sample from a large population and plot each vector in the N-dimensional space. We might find that the resulting points are concentrated on a submanifold of the N-dimensional space, such that a single variable (which is a special linear combination of the N coordinates) captures most of the variation. As an extreme example, imagine the points form a long thin ellipse with one very long axis; position on this long axis almost completely specifies the N vector. The figure below shows real data, ~100k individuals tested. The principal axis of the ellipsoid is g (roughly speaking; as I've emphasized it is not entire well-defined).
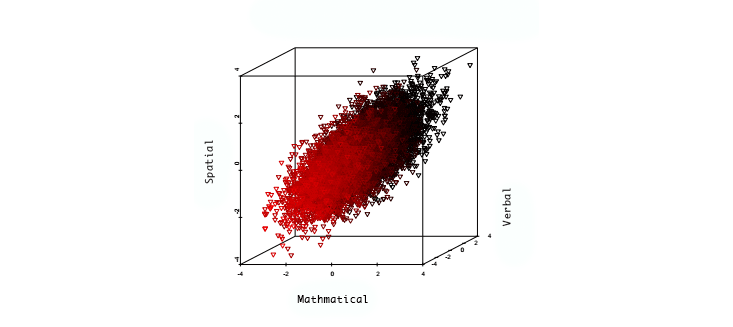
What I've just described geometrically is the case where the N mental abilities display a lot of internal correlation, and have a dominant single factor that arises from factor analysis. This dominant factor is what we call g. Note it did not have to be the case that there was a single dominant factor -- the sampled points could have had any shape -- but for the set of generally agreed upon human cognitive abilities, there is.
(What this implies about underlying brain wetware is an interesting question but would take us too far afield. I will mention that g, defined as above using cognitive tests, correlates with neurophysical quantities like reaction time! So it's at least possible that high g has something to do with generally effective brain function -- being wired up efficiently. It's now acknowledged even by hard line egalitarians that g is at least partly heritable, but for the purposes of this discussion we only require a weaker property -- that adult g is relatively stable.)
To summarize, g is the best single number compression of the N vector characterizing an individual's cognitive profile. (This is a lossy compression -- knowing g does not allow exact reconstruction of the N vector.) Of course, the choice of the N tests used to deduce g was at least somewhat arbitrary, and a change in tests results in a different definition of g. There is no unique or perfect definition of a general factor of intelligence. As I emphasized above, given the nature of the problem it seems unreasonable to criticize the specific construction of g, or to try to be overly precise about the value of g for a particular individual. The important question is Q2: what good is it?
A tremendous amount of research has been conducted on Q2. For a nice summary, see Why g matters: the complexity of ordinary life by psychologist Linda Gottfredson, or click on the IQ or psychometrics label link for this blog. Links and book recommendations here. The short answer is that g does indeed correlate with life outcomes. If you want to argue with me about any of this in the comments, please at least first read some of the literature cited above.
From Gottfredson (WPT = Wonderlic Personnel Test):
Personnel selection research provides much evidence that intelligence (g) is an important predictor of performance in training and on the job, especially in higher level work. This article provides evidence that g has pervasive utility in work settings because it is essentially the ability to deal with cognitive complexity, in particular, with complex information processing. The more complex a work task, the greater the advantages that higher g confers in performing it well.
... These conclusions concerning training potential, particularly at the lower levels, seem confirmed by the military’s last half century of experience in training many millions of recruits. The military has periodically inducted especially large numbers of “marginal men” (percentiles 10-16, or WPT 10-12), either by necessity (World War II), social experiment (Secretary of Defense Robert McNamara’s Project 100,000 in the late 196Os), or accident (the ASVAB misnorming in the early 1980s). In each case, the military has documented the consequences of doing so (Laurence & Ramsberger, 1991; Sticht et al., 1987; U.S. Department of the Army, 1965).
... all agree that these men were very difficult and costly to train, could not learn certain specialties, and performed at a lower average level once on a job. Many such men had to be sent to newly created special units for remedial training or recycled one or more times through basic or technical training.
Limitations and open questions:
1. Are there group differences in g? Yes, this is actually uncontroversial. The hard question is whether these observed differences are due to genetic causes.
2. Is it useful to consider sub-factors? What about, e.g., a 2 or 3-vector compression instead of a scalar quantity? Yes, that's why the SAT has an M and a V section. Some people are strong verbally, but weak mathematically, and vice versa. Some people are really good at visualizing geometric relationships, some aren't, etc.
3. Does g become less useful in the tail of the distribution? Quite possibly. It's harder and harder to differentiate people in the tail.
4. How stable is g? Adult g is pretty stable -- I've seen results with .9 correlation or greater for measurements taken a year apart. However, g measured in childhood is nowhere near a perfect predictor of adult g. If someone has a reference with good data on childhood/adult g correlation, please let me know.
5. Isn't g just the same as class or SES? No. Although there is a weak correlation between g and SES, there are obviously huge variations in g within any particular SES group. Not all rich kids can master calculus, and not all disadvantaged kids read below grade level.
6. How did you get interested in this subject? In elementary school we had to take the ITED (Iowa Test of Educational Development). This test had many subsections (vocabulary, math, reading, etc.) with 99th percentile ceilings. For some reason the teachers (or was it my parents?) let me see my scores, and I immediately wondered whether performance on different sections was correlated. If you were 99 on the math, what was the probability you were also 99 on the reading? What are the odds of all 99s? This leads immediately to the concept of g, which I learned about by digging around at the university library. I also found all five volumes of the Terman study.
7. What are some other useful compressed descriptions? It is claimed that one can characterize personality using the Big Five factors. The results are not as good as for g, I would say, but it's an interesting possibility, and these factors were originally deduced in an information theoretic way. Big Five factors have been shown to be stable and somewhat heritable, although not as heritable as g. Role playing games often use compressed descriptions of individuals (Strength, Dexterity, Intelligence, ...) as do NFL scouts (40 yd dash, veritcal leap, bench press, Wonderlic score, ... ) ;-)
It's a shame that I have to write this post at all. This subject is of such fundamental importance and the results so interesting and clear cut (especially for something from the realm of social science) that everyone should have studied it in school. (Everyone does take the little tests in school...) It's too bad that political correctness means that I will be subject to abuse for merely discussing these well established scientific results.
Why think about any of this? Here's what I said in response to a comment on this earlier post:
Intelligence, genius, and achievement are legitimate subjects for serious study. Anyone who hires or fires employees, mentors younger people, trains students, has kids, or even just has an interest in how human civilization evolved and will evolve should probably think about these questions -- using statistics, biography, history, psychological studies, really whatever tools are available.
85 comments:
You believe in IQ? I guess that means you think every person in the world should be executed except for the one with the highest IQ, right?
Haven't they already found out many of the genes correlated with intelligence, in the human genome?
In order for primates to evolve intelligence, intelligence must have a genetic (inheritable) component.
When you divide up groups, what are the odds the genes for IQ will be distributed evenly, especially if groups evolve on different continents? Watson of course pointed this out, and got in some trouble. I's common sense really. Deep down, even the most liberal of libs, in the heart of hearts, cannot honestly believe in genetic egalitarianism. - "Shawn"
If human biodiversity does not exist, how do Jews, Whites, and Asians become so successful? Must be by holding down everyone else, I mean, what else could it be?
-Shawn
> genes correlated with intelligence, in the human genome?
No, not one so far.
> intelligence must have a genetic (inheritable) component.
Yeah, but that doesnt mean it still has to have a heritable component in humans today. But it does. That component can be quantitated, approximately, from data on twins, despite not knowing what any of the genes (or other sequences) are.
All dogs evolved from a wolf-like animal. Now all dog ethnicities =) , or as we call them breeds, a unique character about them. I propose that human ethnicities should be thought of much in the same way dog breeds are thought of.
This is a little off-topic here but for those who are interested:
http://petrix.com/dogint/intelligence.html
Why does the Border Collie come out so far ahead. The breed must be holding down the Basenjis.
http://www.cscs.umich.edu/~crshalizi/weblog/523.html
A post on factor analysis and the general factor g by a statistician...
Re: A post on factor analysis and the general factor g by a statistician...
I think you've missed one of the main points of the post. If one wants to attack g, one should address Q2, not Q1.
BTW, Cosma is yet another physicist with broad interests and (happens to) teach in a statistics department.
Good on ya Steve. It appears that despite previous comments you DO know what an IQ test is.
I think the reliability (test-retest correlation) for the WAIS after age 17 is more like .97.
Oh and how much of the variance is eliminated with g? Not much if I remember. I think you need three factors to eliminate all but noise on the WAIS.
Interesting post.
Here's a question I've been discussing some while ago. Are there characteristics (intelligence, genius, Big Five?) with the properties that high values are more easily recognized by people who have themselves high values? Take intelligence as an example and you'll see why this is an interesting question. Can you expect that more intelligent people will be better at selecting intelligent people? And exactly what kind of intelligence can you breed this way? I suspect that this may work for some characteristics but not for others.
Technical intelligence (let me call it like this in lack of a better word), in particular when very specialized, is a case where this works very well. When it comes to genius, I have my doubts. And if there's factors relevant for scientific achievement that are not of the category that a high score is useful to recognize another high score, what does that mean for the selection process?
Razib has pointed out that if you carefully parse Shalizi's comments, it turns out that he's not quite the anti-hereditarian IQ denier that people who link to his stuff seem to think.
Not only does Shalizi believe that intelligence, as operationalized by IQ tests, is very important in modern society. He also seems to think that variation in IQ is due to genetics to some extent, and that IQ may be differently distributed in different ethnic groups.
http://www.gnxp.com/blog/2007/11/linguist-i-can-use-r-you-cant-thus-your.php
John Ray commented on his article also.
http://astuteblogger.blogspot.com/2007/11/arrogant-afghan-still-ignoring-basic.html
***genes correlated with intelligence, in the human genome?
No, not one so far.***
“A study on the correlation between IL1RAPL1 and human cognitive ability,”
"In their sample, the L1RAPL1 of 332 children (50:50 male to female), aged 5-14 years old, was screened. The genotype of each child’s L1RAPL1 variant was identified using PCR. In the population, roughly 90% were heterozygotic in the DXS1218 microsattelite variant of L1RAPL1 . Microsattelites are simple repeats of nucleotides in a sequence of DNA, I outlined one way they come about here. The other microsattelite, DXS9896 was present as heterzygotic alleles in 87% of the kids.
Two SNPs are also looked at. 89% of the kids had an A nucleotide in the rs6526806 SNP, where the other 11% had a G. 42% of the kids had one version of the rs12847959 SNP, the other 58% had another version. The authors did not mention what effect these polymorphisms had on the gene, but did indicate they all fall in the intron of the gene — a non-coding region that is spliced out.
The kids were asked to take several cognitive tests that tested their memory, concentration, perception, and verbal abilities. Three of the polymorphisms listed above had effects on memory and concentration. Those that had longer DXS1218 microsattelite variants had lower IQ scores. Similarly, kids with longer DXS9896 mircosattelites also had lower IQ scores. One of the SNPs, rs12847959 showed that individuals that had the CC genotype in the SNP had higher IQ scores compared to those that had the CG genotype. The p-values for all were pretty strict, suggesting that the differences are statistically significant."
http://anthropology.net/2008/05/14/il1rapl1-genotype-intelligence/
unreplicated genetic associations are nearly all false positives
I think you made good points and presented your ideas quite well. I would like to add a few comments.
>Nevertheless, it would be unreasonable to object to this
>definition as a single number characterization of object size,
>given no additional information about the distribution of
>object types.
>
>I suggest we think about IQ in a similar way.
I think not. The reason is that I believe that g is the parameter of interest and IQ is simply one proxy for g (not vice versa). g can be measured about as well by biological ratio scale measurements as by IQ tests. I believe that the difference between IQ and g can be related to intelligence (as we commonly understand it) this way:
IQ = the essence of intelligence, plus varying degrees of noise that relate to broad and narrow abilities
g = the sine qua non of intelligence (Jensen's frequently used description)
>To summarize, g is the best single number compression of
>the N vector characterizing an individual's cognitive profile.
>(This is a lossy compression -- knowing g does not allow exact
>reconstruction of the N vector.) Of course, the choice of the N
>tests used to deduce g was at least somewhat arbitrary, and
>a change in tests results in a different definition of g. There is
>no unique or perfect definition of a general factor of
>intelligence.
You are correct that the choice of tests is arbitrary. In fact, most tests are designed such that they do not measure some known g loaded functions at all. But my reading of your comment suggests a difference between your interpretation of the modeling and that of Spearman, when he noted the "indifference of the indicator." His point was that there is only one g and that any test that loads on g is loading on the same factor. Any narrow test will load on g and the factors that are specific to the narrow ability in question. If you correlate the scores from two tests that do not produce common group factors, the square root of their correlation will be an estimation of their g loadings. This exercise, performed for commonly used IQ tests, yields an average g loading in the 0.80s.
While it is true that the procedure for doing a factor analysis is arbitrary, to the extent that it is possible to define different procedures, the outcomes of different (reasonable) factor analysis procedures show very little quantitative differences. Occasionally research papers will show results for a standard hierarchal factor analysis and for a bifactorial analysis; they show negligible differences. I presume the double extraction is done to show the validity of the methodology.
>1. Are there group differences in g? Yes, this is actually
>uncontroversial. The hard question is whether these observed
>differences are due to genetic causes.
The genetic basis of g has been established to the satisfaction of the vase majority of researchers. In fact, no social factors have been identified that account for any variance in g. The only environmental factors that have been associated with the variance in g are those that act chemically or biologically (such as toxins and diseases). No environmental factor has (to the best of my knowledge) yet been shown to have a long term positive effect on g; environmental factors degrade intelligence.
BobW
>2. Is it useful to consider sub-factors? What about, e.g., a 2 or
>3-vector compression instead of a scalar quantity? Yes, that's
>why the SAT has an M and a V section. Some people are
>strong verbally, but weak mathematically, and vice versa.
>Some people are really good at visualizing geometric
>relationships, some aren't, etc.
It was shown during Spearman's lifetime that there are narrow and broad factors at the 1st and 2nd orders respectively. Even though these can be individually measured, they contribute little to the validity of IQ tests. This is discussed at some length in the section "validity of g for predicting success in job training" [The g Factor]. In very large N studies Jensen reports that the correlation between the subtests' g loading and their validity coefficients is r = +.96. When the non-g variance is examined via the ASVAB, N = 78,049, the average predictive validity was +.02. This is consistent with every study I have seen in which the validity of the residual correlation matrix is determined. The results typically show a validity of 0.0, but some rise to =.04.
There is an interesting, if narrow, exception to the above. The data from the SMPY longitudinal study groups shows a significant advantage for the cohorts who have a math tilt, as compared to those who have a verbal tilt. This shows up in their measures of career success (income, age at tenure, and patents issued). Those individuals, however, are not representative of the full range of intelligence, but are all within the 99th percentile, an area where Spearman's Law of Diminishing Returns has a significant impact on differentiation of ability.
>5. Isn't g just the same as class or SES? No. Although there is
>a weak correlation between g and SES, there are obviously
>huge variations in g within any particular SES group. Not all
>rich kids can master calculus, and not all disadvantaged
>kids read below grade level.
More importantly, g can be seen as a cause of SES and not a consequence of it. For example, siblings statistically fall into SES classes as a function of their intelligence, even though they were reared in the same SES. And... studies of the shared environment have consistently demonstrated that it vanishes by about age 12 and has no impact on adult intelligence.
correlations for IQ to SES:
.30 to .40 children
.50 to .70 adults
BobW
Bee: mining the tail for "true genius" is the hardest problem and probably the thing physicists like you and I are most interested in. But it's quite challenging because of necessarily small statistics and the stochastic nature of success -- did Jane succeed due to internal factors, or was she lucky? Did her oddball approach mean she was creative, and inevitably would have had an important insight, or was it detrimental and nevertheless she was lucky? Very hard to know. I do think some Big Five studies along the lines of the Roe study might yield some interesting results.
BobW,
Thanks for your detailed comments!
"The reason is that I believe that g is the parameter of interest and IQ is simply one proxy for g (not vice versa)."
Yes, you noticed that I was for convenience using IQ and g interchangeably in the post. I assumed the reader would understand that we are trying to measure g and IQ tests are at least slightly flawed estimators of g.
"While it is true that the procedure for doing a factor analysis is arbitrary, to the extent that it is possible to define different procedures, the outcomes of different (reasonable) factor analysis procedures show very little quantitative differences."
When I say g is not uniquely defined I am referring to these small quantitative differences. Also, it's possible for people to disagree about what are "cognitive" factors or tests in the first place, although I think reasonable people would not disagree very much.
Re: sub-factors, it is clear to me as a physicist who knows a lot of humanities professors that "high g" can be expressed in different ways. Knowing that someone has high g *does not predict* (in my experience) whether they are likely to quickly grasp, e.g., the explanation given in the post of factor analysis. (Just imagine the tilted SMPYers.) As you point out, this distinction may only be important in the tail.
Although a *population* analysis shows that people with high g tend to be above average on all factors, certain *individuals* are very lopsided, and for them the value of g does not yield a good estimate of their N-vector cognitive profile. For these atypical individuals, there isn't much meaning or utility in their "general factor" of intelligence. One of the interesting SMPY results (IIRC) is that physicists tended to be high in both M and V whereas in some other mathematical fields one could find high M lower V cases. I seem to find a lot of high M lower V types in software development.
Hi Steve,
Yes, sure, that was not a good example. Then take something else. My question is whether there are properties that raise the skill of detecting the same property and are thus to some extend capable of self-selection, and others that aren't. Take reliability if you like, maybe that's a better example. Is somebody who is reliable more likely to correctly identify somebody who is also? If you continue the thought this brings you eventually to the question whether committees constituted of people who are successful in doing A are the right ones to select further people who have good changes of being successful in doing A. Best,
B.
"...the question whether committees constituted of people who are successful in doing A are the right ones to select further people who have good changes of being successful in doing A."
Again a tricky question. On the plus side a successful A-er has detailed A domain knowledge, understands the specific challenges, etc. On the minus side all the successful ones might have been *lucky* and that distorts their perspective.
An example of the latter case: when I talk to successful VCs and entrepreneurs, who have succeeded in a very high vol environment, they tend to over-extrapolate the importance of their own specific experiences, not realizing that it might have been blind luck which let them succeed, rather than any specific decision they made.
Yes, I understand the point about luck. That's relevant to correctly rate somebody's skills to begin with, but that wasn't the point I was aiming at. Just assume, however unrealistic that may be, that all the A-ers are indeed there because they have high A skills. Then it's still not clear they are good at identifying A. Rather, what might happen is that the A-ers, unable to correctly identify what marks their skill, look for people that remind them of themselves for whatever reasons (I was just like him at this age!). You mix that with their believe that just being A makes them good at identifying A and figure that this selection process is bound to be a disaster.
Yes, I agree. Said another way it's hard to look back at your own success (assuming you had some, and assuming it wasn't due to luck) and figure out what the main contributing factors were. Add to that the tendency to like people like yourself, and you've got plenty of uncertainty in any hiring decision.
Speaking of that, I'm chairing a search this year and I'm told we have 300 applicants (lots of other schools have hiring freezes this year, so we have more applicants than usual)!
Which reminds me of the 250 applications I'm supposed to read within the next 2 weeks. Argh.
And then there's the people who don't like people like themselves. As in, don't want them to be more successful. Complicated, complicated.
Large differences in subtest scores are more common the higher the full scale score, no?
Or, put another way, g means less the higher the IQ.
Non-g variance in subtests has negligible predictive validity?
What does that mean operationally?
It cannot be that the the three factors of verbal, visio-spatial, and attention have negligible validity within certain occupational/academic fields.
But Bob W's uncritical acceptance of race and IQ data show him to be on the wrong end of the physicist bell curve.
***But Bob W's uncritical acceptance of race and IQ data show him to be on the wrong end of the physicist bell curve.***
If you disagree with him, say why. Play the ball not the man, as they say.
anon, its possible that the non-g variance doesnt have a big enough effect to be measured easily. After all, even g does not explain that much of the variance in job performance at the individual level (I believe the importance of IQ increases with the cognitive demands of the field).
(I always wonder if it might explain more of the variance in economic performance at the aggregate level -- ie the mean IQ of my corporation vs that of your corporation.)
The mean difference in IQ upon retest, if I recall, is 4 points. And the SD is of course 15. I'm not that quantitative, and especially not statistical, but that seems to me like its probably a good index of the noise, which is small but nontrivial. And there is probably noise in job evaluations too.
The ball not the man... But Bob W is like a dog who runs onto the field, steals the ball, and starts chewing on it.
There is no disagreeing with the dog.
Eric, I think the non-g variance on WAIS subtests is between 30% and 75%.
Also an IQ test needn't be a battery even if theory requires it. The Raven's has only one type of question.
Jensen's idea that combining reaction time, brian size, etc. can give him nearly the same g that an IQ test gives is just PURE FANTASY.
***Jensen's idea that combining reaction time, brian size, etc. can give him nearly the same g that an IQ test gives is just PURE FANTASY.***
Maybe, but it isn't fantasy to think that brain imaging could complement psychometric measures.
"Our neurometric model of IQ contributes to a literature showing that brain images can be used to predict complex behaviors and traits (Haynes and Rees, 2006; Knutson et al., 2007). Although our model still does not approach the predictive power of psychometric tests, its high accuracy suggests that neurometric assessments of intelligence may soon become a useful complement to psychometric test. For example, brain images might be used to improve intelligence estimates for individuals whose psychometric scores systematically underestimate their IQ. We hope that future research will build on our neurometric model of intelligence, both refining it so that it generalizes to other populations and expanding it to enhance its accuracy."
http://www.jneurosci.org/cgi/content/full/28/41/10323
This comment was posted by BobW earlier at 9:23 AM, but I took it down and replaced it here because it contained some personal information that I've now removed.
BobW:
>Although a *population* analysis shows that people with
>high g tend to be above average on all factors, certain
>*individuals* are very lopsided, and for them the value of g
>does not yield a good estimate of their N-vector cognitive
>profile.
Yes, there is no question about that. It is also well known that factors other than intelligence contribute to how people direct their lives. Among these things are specific interest, zeal, persistence, and personality.
> For these atypical individuals, there isn't much
>meaning or utility in their "general factor" of intelligence. One
>of the interesting SMPY results (IIRC) is that physicists tended
>to be high in both M and V whereas in some other
>mathematical fields one could find high M lower V cases. I
>seem to find a lot of high M lower V types in software
>development.
If you have time to grab one of those lists of GRE scores and intended majors, you will find it difficult to ignore. Basically, physicists score at or near the top in both math and verbal. Lawyers score relatively far behind in both areas. I got into a discussion with La Griffe once about the verbal abilities of lawyers. He argued (obviously without first checking the facts) that people with very high verbal scores go into law. I tabulated a number of selected majors from the GRE list and showed him that there were lots of rather unexpected fields of study in which the applicants held higher verbal scores than lawyers. I have looked at more than one of these tabulations and recall that at least one showed the highest combined scores were held by those who wanted to major in philosophy. I vaguely recall that this did not show up in all of the reports I examined (from different years, but I only looked at a few).
Basically, I think it goes back to g, with a little math spice added. A few fields attract the truly bright people. Of those math and physics are at or near the top. Even so, I agree with your general observation concerning M & V. There is also a between group effect that is sufficiently strong that it cannot be ignored. It is that among East Asians there is a rather strong M tilt.
9:23 AM
To some extent, Steve, aspects of this debate weary me in the sense that when I was young I used to like to debate "flat earthers", but no longer. Can you point us at a good treatise on why the PC public and academics alike are so keen on denying the scientific facts surrounding IQ?
For myself, I think the debate is, perhaps, best focussed on the obstruction rather than discussing whether or not we believe in "the germ theory of disease" vs. "the miasma theory".
Apoligies if you have already covered this sub-topic and I haven't seen it. Why do so many deny the facts? What is their goal?
Who's denying the facts LY? The facts are the facts and interpretations are interpretations, though some don't know the difference.
Because the ideological implications are so great greater skepticism is warranted, even among experts.
***Can you point us at a good treatise on why the PC public and academics alike are so keen on denying the scientific facts surrounding IQ? ...
Why do so many deny the facts? What is their goal?***
The book by Mark Snderman & Stanley Rothman 'The IQ Controversy' discusses the results of their anonymous survey, the way the media distort unfavourable academic opinions, and possible reasons for doing so.
Review here by Dan Seligman, who also wrote an interesting book 'A Question of Intelligence' which discussed why it is a taboo subject.
http://www.commentarymagazine.com/viewarticle.cfm/the-iq-controversy--by-mark-snyderman-and-stanley-rothman-7538
Steven Pinker's book 'The Blank Slate' doesn't really focus on IQ, but does discuss how Boasian/environmentalist viewpoints came to dominate psychology & how they underpin social & political beliefs.
If you read about the hostility to sociobiology in the 70's a lot of it seems to be driven by fears that it will justify inequality or discrimination.
Kanazawa has a good post here about the naturalist & moralistic fallacies which should be avoided:
"Both are logical fallacies, and they get in the way of progress in science in general, and in evolutionary psychology in particular. However, as Ridley astutely points out, political conservatives are more likely to commit the naturalistic fallacy (“Nature designed men to be competitive and women to be nurturing, so women ought to stay home to take care of the children and leave politics to men”), while political liberals are equally likely to commit the moralistic fallacy (“The Western liberal democratic principles hold that men and women ought to be treated equally under the law, and therefore men and women are biologically identical and any study that demonstrates otherwise is a priori false”).
Since academics, and social scientists in particular, are overwhelmingly left-wing liberals, the moralistic fallacy has been a much greater problem in academic discussions of evolutionary psychology than the naturalistic fallacy. Most academics are above committing the naturalistic fallacy, but they are not above committing the moralistic fallacy. The social scientists’ stubborn refusal to accept sex and race differences in behavior, temperament, and cognitive abilities, and their tendency to be blind to the empirical reality of stereotypes, reflect their moralistic fallacy driven by their liberal political convictions..."
http://www.psychologytoday.com/blog/the-scientific-fundamentalist/200810/two-logical-fallacies-we-must-avoid
It's not convictions so much. It's more a matter of taste, and on the part of academics resentment.
Always there has been a story which explains why the haves have and the have-nots have not.
The haves say to themselves and everyone else, "We have because we are better, smarter, harder working, etc."
This story has a name: "ideology".
"The ruling ideas of any age have ever been the ideas of its ruling class."
***Always there has been a story which explains why the haves have and the have-nots have not.
The haves say to themselves and everyone else, "We have because we are better, smarter, harder working, etc."
This story has a name: "ideology".
"The ruling ideas of any age have ever been the ideas of its ruling class."***
I think that's Kanazawa's point - scientists should care only about what is. If you look at the response to sociobiology you have a clear example of scientists being more concerned with their ideology (apparently marxism in that case). EO Wilson wrote about this:
"In formulating sociobiology, I wanted to move evolutionary biology into every potentially congenial subject, including human behavior and even political behavior, roughshod if need be and as quickly as possible. Lewontin obviously did not.
By adopting a narrow criterion of acceptable research deserving the title of science, Lewontin freed himself to pursue a political agenda unencumbered by science. He purveyed the postmodernist view that accepted truth, unless based upon unassailable fact, is no more than a reflection of dominant ideology and political power. After his turn to political activism, around 1970, he worked to promote his own accepted truth: the Marxian view of holism, envisioning a mental universe within which social systems ebb and flow in response to the forces of economics and class struggle. He disputed the idea of reductionism in evolutionary biology, even though it was and is the virtually unchallenged linchpin of the natural sciences as a whole. And most particularly, he rejected it for human social behavior. He said, in 1991, "By reductionism, we mean the belief that the world is broken up into tiny bits and pieces, each of which has its own properties and which combine together to make larger things. The individual makes society, for example, and society is nothing but the manifestation of the properties of individual human beings. Individual properties are the causes and the properties of the social whole are the effects of those causes. "
Now this reductionism, as Lewontin expressed and rejected it, is precisely my view of how the world works. It forms the basis of human sociobiology as I construed it. But it is not science, Lewontin insisted. It cannot be made into science. And according to his own political beliefs, expressed over many years, sociobiology or any other social theory based on the biology of individuals cannot even possibly be true. Here is how he summarized his postmodernist argument: "This individualistic view of the biological world is simply a reflection of the ideologies of the bourgeois revolutions of the eighteenth century that placed the individual as the center of everything."
That much being understood, Lewontin concluded, and the shackles of bourgeois ideology cast aside, we are then freed to proceed along more progressive--that is to say, Marxist--political guidelines. These do not require scientific validation, at least not by any connection with genetics, neurobiology, or evolutionary theory. The genes, Lewontin declared, "have been replaced by an entirely new level of causation, that of social interaction with its own laws and its own nature that can be understood and explored only through that unique form of experience, social action." Hence the inviolable wisdom of Marx, Lenin, and Mao to which he alluded elsewhere....
Here then is the argument in its raw form: only an anti-reductionist, non-bourgeois science can help humanity attain the highest goal, which is a socialist world."
Science and ideology by Edward O. Wilson Vol. 8, Academic Questions, 06-01-1995.
Wilson finishes with another example of ideology and science:
"The sociobiology controversy as an example is not unique in recent history, although I wish it were. On 16 May 1986, a group of academic luminaries, including Robert Hinde, John Paul Scott, and several other prominent behavioral scientists, issued the Seville Declaration (following a conference in Spain), declaring invalid any theories or claims that aggression and war have a genetic basis. Such thinking is according to them, "scientifically incorrect." "Wars," the Declaration said, "begin in the minds of men." Warfare is a product of culture; biology contributes only in providing language and the capacity to invent wars. Case closed. The authors of the Declaration suggested, in effect, that if you have any thoughts otherwise about these matters, keep your mouth shut. The Seville Declaration was adopted that same year as the official policy of the American Anthropological Association. Eighty percent of the members who returned ballots on the motion to adopt voted in favor. Virtually all the main premises and conclusions of the Seville group are contradicted by the evidence, but no matter- -the Declaration seemed to its signers and ratifiers the politically and morally correct thing to do. All the participants must have felt good about supporting it.
But as we shall see as the new IQ wars develop over the coming months [they have since proved virulent on the anti-genetic side--Author], as ideologues on both sides spring into their accustomed positions, feeling good is not what science is all about. Getting it right, and then basing social decisions on tested and carefully weighed objective knowledge, is what science is all about."
When family background and education are controlled for does IQ have any validity?
Steve's eminent scientists thing was a joke.
> Eric, I think the non-g variance on WAIS subtests is between 30% and 75%.
I sort of assumed we were talking about instruments highly correlated with g, like Raven's. Do people actually examine the g - performance correlation using less g-loaded stuff? I wouldnt know. (I confess, psychometrics isnt my main squeeze and I havent read much journal literature, though Ive read limited parts of Jensen's book. I also fail captchas regularly.)
> Always there has been a story [...] "We have because we are better, smarter, harder working, etc." [...] This story has a name: "ideology".
Gosh, what a joy it must be to stand on the non-ideological side -- in a parallel universe where Marx was a greengrocer and Lysenko was eaten by wolves, to be specific. When I'm finally ready to face reality, I'll have to dig up some of those Soviet genetics journals and experience my own personal super-objective re-edification camp.
***When family background and education are controlled for does IQ have any validity?***
Apparently so.
Rowe, David C.; Vesterdal, Wendy J.; Rodgers, Joseph L. . Hernstein's Syllogism: Genetic and shared environmental influences on IQ, education, and income.
Intelligence. 26, (4), 405-423.
Also see Murray's paper here.
http://www.aei.org/docLib/20040302_book443.pdf
I don't stand anywhere Eric. Or do I?
I'll restate the question.
When if ever are the correlates of IQ the effects of IQ? When is IQ a cause of the outcomes it is correlated with?
***When if ever are the correlates of IQ the effects of IQ? When is IQ a cause of the outcomes it is correlated with?***
"Deary took the analysis a step further however and did a little latent variable modeling. As the IQ test had three components/subtests (verbal, nonverbal, quantitative), he correlated a latent g factor with a latent academic factor using the following subtests: English, English Literature, Math, Science, Geography, French (n=12519). The correlation between the latent factors was .81. That is: 66% of the variance in latent (general) academic achievement can be explained by latent cognitive ability---measured 5 years previously. While he hypothesizes that such things as "school ethos" and "parental support" are good areas to search for the other 34%, based on Rohode's work, it is likely going to be found in residual, first order factors (see Carroll or McGrew).
Take home message: While general cognitive ability and academic achievement are not isomorphic, the former is necessary for the latter, while the converse is not necessarily true. Spearman suggested this more than a century ago, and, to quote the last sentence in Deary's work,
These data establish the validity of g for this important life outcome."
http://www.gnxp.com/blog/2007/01/iq-academic-achievement.php
Ok, so it's well established that IQ/g have strong predictive power, but what is the evidence that IQ/g is actually causing the outcomes its predicting? An IQ test is measuring many, many things that it's correlated with (and not just some [limited] measure of SES).
The argument that g is a good measure of what most people think of as intelligence seems pretty strong to me, on the other hand. I haven't read much on that part of the debate, but the fact that all of these cognitive tests are correlated with each other suggests that there is something called intelligence and that we can measure it.
There is something. There is no doubt. But what is that something.
I'll restate again.
If by validity is meant earned income, then when level and kinf of education and family background are controlled for is any of the residual variation in earned income explained by IQ?
My experience (and perhaps the data?) indicates that the effect of IQ on earned income is almost 100% mediated by education.
Ben017,
You didn't answer my/anon's question. The fact that IQ can predict achievement well, and that g can predict achievement even better, does not mean that either is doing (the bulk of) the causing.
Just as correlation is not causation, prediction is not causation.
Good on ya ben. This is something that Steve and his ilk don't get even though they think they do.
Steve is obsessed with IQ. His sort is attracted to theoretical physics. After all, he thinks, who could be smarter than a thoeretical physicist.
Well I can answer that. Someone who wants to make a difference, cure disease, etc.
anon, Steve has addressed your causation question in the past. For the high-IQ subjects studied by Terman, being a physicist didnt raise the IQ that had been measured in the past. Nor did a job in business lower it. Vocation does not alter one's IQ. As for plasticity of IQ when one is not yet adult, many scientific attempts have been made to find some program which could raise IQ. It hasnt worked. Ergo IQ is not the result of education.
You should also note that the variance of IQ within families is not that much smaller than the within-race variance of the population. Unfortunately I forget the exact value. That there is so much difference between siblings, strongly suggests (by the law of large numbers) that the heritable component of IQ is not forged by hundreds of different common genetic variants. It must very probably be forged, mostly, by the presence or absence of a modest number of rare, modestly deleterious alleles. A priori it could also be shaped by few common variants, but it seems pretty clear from experiment that this is not true.
No. Neither you nor Steve has addressed my question on IQ validity. Forget about it. I might as well be speaking a foreign language.
Eric,
1. I don't think you're actually addressing the larger point about causation. Education, SES, etc. are not the only things which correlate with IQ and might independently contribute to income. People go from the fact that IQ/g predict later income/education to claiming that it causes such things. But that isn't warranted
2. I haven't read enough about the Education and IQ debate, but I think that your summary and interpretation of the evidence may be off. To begin with, there is solid evidence of interventions that work. There was a study of low income children in France being adopted into higher income homes that showed something like a 9 to 12 point IQ gain.
Secondly, my understanding is that educational interventions do in fact increase IQ, the problem with most of them is that they do not have a lasting effect on IQ. This leads to the question of whether an intervention that lasted beyond the younger years might succeed in permanently increasing IQ.
Lastly, I want to note that-- as with all things in the IQ debate-- this whole discussion requires a lot of complex statistical thinking and reasoning. One issues that come to mind is the operationalization of "education" and "socioeconomic status". Education is typically operationally defined here as years of education, and in some cases it may incorporate the quality of an educational institution. But does that really capture actual education, of the type that makes people smarter? I would say it doesnt. A key factor is not just that students are in the room while the high-quality class is being taught, but that they are receptive, interested, and devoted to the classroom material. And what determines that is not just IQ but things like work ethic, conscientousness, and values.
Many people cite this study by Charles Murray to say that SES has no significant impact on IQ. But note how SES is operationalized.. if you're in the same family as someone you were raised in the same SES. But that's not how SES works. It changes over time. My brothers, for example were raised in a lower SES home than me because they were born when my family was poorer.
In summary, this is a very complex debate and I would urge against quick "Ergos" at the current state of the research.
Another fact about which Steve seems to be unaware is that linear factor analysis and Pearson's correlation are of dubious significance and are certainly misleading when the joint distribution is not multivariate normal.
This is shown glaringly by the extent to which the heritability of IQ or g varies with SES.
The surface which minimzes the loss function (X - x)^2 is linear for the multivariate normal distribution, but not for real distributions.
Good physicist that he is, Steve is predisposed to confuse model and reality. This was brought home by his speaking of evolution as improbable, as if probability were a characteristic of the thing in itself.
Anon and Ben g,
Anon was concerned with education -- thats why I focused on education, plus education-like influences such as ongoing vocational activites. I did not claim to address all environmental variables, just one.
I did make a bad logical error, though. I suggested that if IQ and education are correlated, but education doesnt alter IQ, then IQ must alter education enough to account for the whole correlation. Whoops! This is logically false because a third variable might alter both education and IQ.
However, Anon's whole question is also logically erroneous, if and only if he is trying to support the left's worldview on the distribution of wealth. Confirmation of his hypothesis actually cannot support that worldview, at least not by itself. Anon wants to correct for family background, that is, compare people whose family backgrounds are the same (for whatever family background variable Anon is interested in). That much is fine. But Anon *also* wants to correct for some "education" variable, and only *then* see whether IQ correlates with income (performance). This is questionable. Effects of IQ on income, via education, may exist. But this is actually a "valid" and "fair" way for IQ to have a "legit" influence on income/performance. Valid because IQ probably *causes* much or all of the difference in education (a difference which we have already corrected for family background), rather than being non-causally correlated with it. Fair because this quite possibly cannot be altered by some interventionist (leftist) government program: high-IQ people received more education which improves their performance, but it does not follow that low-IQ peoples' performance would benefit in the same way from greater education.
To boil it down, Anon probably thinks that proving his hypothesis (no IQ-performance correlation after correcting for education) would support his "worldview" (that government intervention in the natural distribution of education, can somewhat reduce the equality of the performance/income distribution). In truth, confirmation or falsification of his hypothesis cannot confirm or deny that there is any truth in the leftist worldview on these matters. Also, even if we do prove somehow that all the variance in wealth due to IQ is "fair" in practice because it is not remediable by government social programs, there is still the question whether the *rest* of the variance in income is "fair."
- - - -
Also, while maybe I should have been explicit, when I mentioned "effects on IQ" I did mean "lasting effects". IQ jocks know that childhood IQ is less stable thus less "meaningful," and that gains from programs for children havent been found (so far) to last into adulthood.
My "ergo" is just a nice short word for showing my reasoning. I didnt mean to imply that there is, say, a less than 0.1% chance that any intervention will ever be found to raise adult IQ in the USA context. (Naturally, replete nutrition can raise it in contexts where many people are in severe want.)
> But that's not how SES works. It changes over time.
This could certainly mess up the results, but only if there is a fair amount of change in SES on average. I dont think there is, on average. What you said impugns the validity of the study a little bit, but if you want to "really" impugn it, you would have to show that the average household had an income change that was relatively large.
Anon, what you just said was way over my head -- but just in case I did actually semi-grasp it, my impression was that Bob already addressed the "arbitrariness" of principal component analysis. If that was what you were talking about.
And we can all see the arbitrariness in the Pearson correlation coefficient, which at least gives math-mortals like myself a crude model for what I think you are saying.
***There was a study of low income children in France being adopted into higher income homes that showed something like a 9 to 12 point IQ gain.***
This is discussed by Nisbett in his book 'Intelligence & How to Get it'. There is a review here by Richwine which suggests he might be overstating the case.
"He cites instead eight other adoption studies—three directly, five via reference to a review article—that compare poor children adopted into wealthier homes with similar poor children who were not adopted. He concludes that the IQ gain for adopted kids is “between 12 and 18 IQ points,” a strong claim. A 15-point change in IQ is one standard deviation—the difference between well below average and well above.
Nisbett makes these adoption studies the crux of his argument because they allegedly demonstrate the great possibilities of environmental intervention. He goes into great detail about how differences in parenting styles could affect a child’s intelligence. He acknowledges that the correlation between bad parenting and low child IQ could really be due to genetic transmission, but he says that cannot be true because we know from adoption studies that home environments matter so much.
The problem is that none of the eight adoption studies Nisbett references show adult IQ scores. The last IQ evaluations of the adoptees typically occurred in the early teenage years and even earlier in some cases. It is well-known that the effects of the home environment are significant through early adolescence, and they do not typically fade until the late teens and early 20s. The studies Nisbett cites as “proof” that home environments matter are not inconsistent with the hereditarian view....
"Abecedarian and IHDP were much more respectable experiments, which claimed IQ gains of about five points by adulthood. These results are disputed—the Abecedarian control group may have had a lower initial IQ than the treatment group, and only the higher birth weight babies in IHDP showed any gains—but the technical details are less interesting than the narrow scope of the debate. The success stories, which require the most optimistic read of the data, involve raising IQ by five points or less. When success means moving people from the 16th to the 25th percentile of IQ as Abecedarian did, a strong dose of realism about raising IQ is needed."
http://amconmag.com/article/2009/oct/01/00048/
not only "well established" results says Steve, but "well established scietific results".
well if they is sci-uhn-tif-ic they mustes be right. it's science fool.
"To summarize, g is the best single number compression..."
No. No. And once again no. It is not the best.
anon, since you are so smart, probably non-trivially smarter than me (I am not being sarcastic), why the unsupported comments like your last two. You didnt even name what single number is better than g. If you had less wattage upstairs I would just ignore this, since people love to make claims they cant support (including me when my discipline falters), but clearly you are more than able to support these ones.
Also, I'll assume you more or less concede to my point, that it is not appropriate to correct for education before examining the IQ correlation to performance/income, because higher IQ may directly cause higher degree of education.
> not appropriate [...] because higher IQ may directly cause higher degree of education
It would almost be a little like correcting for score on a test of general factual knowledge -- and only then looking at the remaining IQ - performance correlation.
Clearly its wrong when seeking correlation to correct for one of the effects of one of the variables. I dont know enough logic or stats to state and justify what I'm perceiving in a canonical way, so thats the best I can do. I'm less good quantitatively than verbally.
"politcal correctness" has itself become a term like "racist" or "homophobe". whatever it meant originally, it means more now or it means so many things it is meaningless.
A test which incorporates non-g characteristics like creativity would produce a single number "score" with more predictive validity than an IQ/g score. I read that Sternberg created such a test and that it predicted work performance better than IQ alone by a significant amount.
====
Another comment on the IQ/education thing, which I think might clear up some of the confusion between anon, eric, and Ben017:
IQ's validity in predicting outcomes comes from two things:
#1: Causing variance, directly or indirectly, in those outcomes. For example, if IQ is responsible for a certain portion of educational success.
#2: Correlating with things that it doesn't cause, that contribute to outcome variance. Such correlations may exist because of genetic or environmental factors that effect both, or in some situations the other thing may be causing variance in IQ.
The point being made by Ben017 and Eric is that attempts at improving education tend not to increase adult IQ, implying that variance in educational quality (within a normal range) is not responsible for increasing IQ. From this, Eric wrongly jumps to the conclusion that education need not be controlled for when assessing the independent validity of IQ, as if education were simply the result of IQ.
As Eric mentioned earlier, but seems to have forgotten, this is a "bad logical error." It forgets that, even if education does not cause IQ, it is not correlated with IQ solely because it is caused by it. Tertiary genetic and environmental variables help link these two together.
Thus, to determine how much IQ itself is independently contributing to economic and occupational outcomes, we need to control for education to the extent that it is not caused by IQ.
I don't know of a study which properly controls for education in that way. If anyone does, a citation would be great.
In the mean time, we'll have a great number of people ignorantly running around saying that "intelligence" (as measured by IQ tests) is responsible for the entire predictive validity of IQ.
> Thus, to determine how much IQ itself is independently contributing to economic and occupational outcomes, we need to control for education to the extent that it is not caused by IQ.
I agree with you totally on this view. And, contra what you say, the error of mine that I pointed out before, was not a basis for my coming (later) to this view. Look, if you really feel like re-reading my poor writing, and you will see I had different reasons. And I too pointed out that not *all* variance in education has to be caused by IQ.
However, its true that my writing was very turgid as well as vague. I just couldnt do much better.
> I don't know of a study which properly controls for education in that way.
Well, I agree that we need to "control for education to the extent that it is not caused by IQ." But how? Is it even possible to separate the educational variance caused by IQ, from the educational variance not caused by IQ? Perhaps correcting for SES comes close to doing what we want to do, but how do we prove or disprove that?
Is there reason to believe that genes for performance-related traits, such as diligence, are strongly linked to IQ by assortive mating? (Diligence and IQ seem to both be associated with asian-ness, but I'm talking within-group here.) Beauty doesnt seem to be all that strongly linked to IQ. Not as much as I would have thought. Is assortive mating, perhaps, not all that terribly powerful in creating correlations between different good traits?
The correlation that I seem to recall between IQ and grades is 0.50. Does that tell us anything?
> A test which incorporates non-g characteristics like creativity would produce a single number "score" with more predictive validity than an IQ/g score.
Quite interesting idea. I agree that such a number would be better, if creativity can actually be measured and is at least partly separate from IQ. It would be great to measure creativity separate from IQ, and see how much they correlate, but can it be done?
Is creativity part of intelligence and part of solving some IQ test problems? Its certainly part of solving "think out of the box" riddles. Dont many IQ test questions involve the same thing, in a lesser degree?
Murray, et al would like to use IQ to explain why things are the way they are, but in the end all they can do is describe how they are.
>I don't know of a study which properly controls
>for education in that way. If anyone does, a
>citation would be great.
See page 97 of The Bell Curve:
"We know that the correlation between intelligence and income is not much diminished by partialling out the contributions of education, work experience, marital status, and other demographic variables. Such a finding strengthens the idea that the job market is increasingly rewarding not just education but intelligence." [see Blackburn and Neumark, 1991]
>In the mean time, we'll have a great number of
>people ignorantly running around saying that
>"intelligence" (as measured by IQ tests) is
>responsible for the entire predictive validity of
>IQ.
The predictive validity of IQ is due to its g loading, not to errors or specificity.
Interesting, Bob. Striking that that works. I say that because it sounds like an over-conservative test -- that is, I imagine you would agree with BenG and I that its not appropriate to partial out *all* the effects of education, since IQ probably causes some of that variation.
Was the kind of education controlled for? Of course not.
If were shown that IQ was a strong predictor of earned income in middle age for 100 Cal-Tech EE graduates all of whom came from two parent upper middle class homes that would be very interesting. But my guess is the range of IQs would be too restricted.
Sorry guys, I've lost track of this thread -- too busy with other stuff the past few days -- so perhaps I am confused about what you are discussing.
But doesn't the Dale and Krueger data show that the kids whose SATs were high enough that they could have attended an elite university make as much money as the elite grads even though they attended a less elite university? So it doesn't seem like the fancy education is causing the high earnings later in life. (Sorting and signaling, not human capital building...)
See also the UT Austin data I linked to. They break it out by major and SAT score. SAT definitely seems to have an effect, although choice of major does as well. These kids all went to the same school...
Who is being compared here? Is this article available for free?
Is it those who were accepted and attended Harvard, Duke, etc. with those who were accepted but didn't attend?
Furthermore, Penn St and Dennison are still above average.
Were it shown that students who scored above the 95th ptile and who were rejected by Harvard, Duke, etc. and then attended Cleveland State, Cal St Northridge, etc. still had the same earnings THAT would mean something.
What is plan II in the UT data.
The difference in mean SAT with major is remakably small. Less than 1300 on the new SAT for engineering majors making 100k+?
Plan II is UT's honors college. To qualify you have to be a strong HS student, but I think within Plan II there are a variety of possible majors.
A commenter noted that the SAT avgs of the other majors are reduced because the good people in those majors tend to be listed as Plan II.
But I believe the PlI people take most of their classes with the regular UT students. There might be some special PII course offerings, but big standard courses like physics for engineers or theory of circuit design would not have special PII sections.
So it's hard to argue that the PII education is that much better than the general UT one, although PII people probably hang around other high achieving PII people, which could make a big difference.
If you google around you can probably find the Dale and Krueger study -- it got a lot of attention.
BobW (and Steve Hsu),
Haven't looked into that study myself (nor can I even find the study on Google Scholar), but findings like this suggest that college education is more important than IQ in determining later income:
http://www.gnxp.com/blog/2008/09/college-is-still-best-pay-off.php
There's an extensive scholarly literature beyond that which supports the proposition of that article. For example, a behavior genetic study by Rowe concluded a "a correlation of 0.63 between IQ and education and 0.34 between IQ and income". In short, Murray appears to be wrong about IQ being more important than education.
Also, as anon pointed out, we have to ask about not just years of education but the quality/nature of it.. and its not clear how that study operationalized "education."
You write that:
The predictive validity of IQ is due to its g loading, not to errors or specificity.
This ignores that g is correlated with plenty of inputs to income that are independent from what the tests directly measure.
Dale and Krueger:
http://www.mitpressjournals.org/doi/abs/10.1162/003355302320935089
Estimates of the effect of college selectivity on earnings may be biased because elite colleges admit students, in part, based on characteristics that are related to future earnings. We matched students who applied to, and were accepted by, similar colleges to try to eliminate this bias. Using the College and Beyond data set and National Longitudinal Survey of the High School Class of 1972, we find that students who attended more selective colleges earned about the same as students of seemingly comparable ability who attended less selective schools. Children from low-income families, however, earned more if they attended selective colleges.
But see here for more analysis and some criticism:
http://www.marginalrevolution.com/marginalrevolution/2009/03/what-does-the-dale-and-krueger-education-paper-really-say.html
http://www.overcomingbias.com/2009/03/college-prestige-matters.html#more
More here:
http://infoproc.blogspot.com/2009/10/selectivity-of-us-colleges-and-returns.html
ben g:
>In short, Murray appears to be wrong about IQ
>being more important than education.
Where did Murray express that idea??? To the best of my knowledge he neither believes that nor has he written or said it. If your information is based on the material I cited, you did not read it carefully. Repeated again for your benefit:
See page 97 of The Bell Curve:
"We know that the correlation between intelligence and income is not much diminished by partialling out the contributions of education, work experience, marital status, and other demographic variables. Such a finding strengthens the idea that the job market is increasingly rewarding not just education but intelligence." [see Blackburn and Neumark, 1991]
>Also, as anon pointed out, we have to ask
>about not just years of education but the
>quality/nature of it.. and its not clear how that
>study operationalized "education."
What is "that study?"
>You write that:
>The predictive validity of IQ is due to its g
>loading, not to errors or specificity.
>
>This ignores that g is correlated with plenty of
>inputs to income that are independent from
>what the tests directly measure.
You can determine g by measuring just the ability of a person to complete a set of matrix test items. That g is the same as g determined by other tests that do not contain matrix test items. You can also get a very nice g measurement from the pedigree test. None of the test items need to involve the correlates that can be found with g (longevity, health, income, law-abidingness, job performance, scholastic performance, etc.). The bottom line is that income rises as a function of g and is close to linear over the entire distribution range. This applies both to the range that typically includes many college graduates and over the range that typically consists of high school dropouts. The many advantages of g combine (as you suggest) to produce various outcomes, such as income.
BobW,
I misread part of your post. Tell me if I am correctly summarizing your view:
"IQ predicts education, and income quite well. Education predicts income even better than IQ. IQ's prediction of income is not very contingent on its correlation with education, though."
If that is not your view, please clarify further. If it is your view, can you explain how Education is such a powerful predictor of income and yet controlling for it doesn't much limit IQ's predictive power of income?
===
Secondly, in regards to g.. I don't think youre addressing the point I'm making. g is intended as a measure of "general intelligence." people like yourself observe that g predicts life outcomes and from there infer that variance in these outcomes must be due primarily to variance in a generalized intellectual capability. however, this ignores that g correlates with things that are not forms of intelligence, and that much of its predictive validity may derive from such things.
Oh no ben that's a point too subtle for Bob. You can restate it a thousand times. He still won't get it.
That the Raven's, which is not a battery, measures g as well as any test which is a battery means that g is 100% bollocks.
In 30 years Raven's IQ increased by 30 points in the Netherlands. Has g? The Raven's is bollocks.
If only Bob were a Dutchman.
How many angels can fit on the head of a pin?
Bob has an answer.
***How many angels can fit on the head of a pin?
Bob has an answer.***
Why so hostile? Spare the personal abuse, it makes you sound pathetic.
The debate over IQ is equally absurd. It is carried on by exactly those academics with the lowest mean IQ (among academics).
Oh I am quite pathetic I'm sure, but none are more pathetic than the crypto-klansmen IQ mavens.
Attacking such on their own IQ is quite amusing to me even if they don't listen.
A spade is a spade, and Bob W hates spades.
On a single measure better than g.
Given a large data set from a battery like the WAIS or even better a battery of batteries, rather than assume the pdf is multivariate normal, "fit" a pdf to the data using a Gaussian or other fast converging basis set.
Then the shape of the best fit one dimensional curve, two dimensional surface, hypersurface, etc. for one factor, two factors, three factors, etc. is determined by this best fit pdf, and the factors are any arbitray parameters used to parameterize these surfaces.
These surfaces will not be linear. They are determined by the pdf as those surfaces which minimize some loss function such as (X - x)^2.
This mathematics is primitive compared to what Steve deals with, but at the same time beyond any professional IQ researchers.
>I misread part of your post. Tell me if I am
>correctly summarizing your view:
>
>"IQ predicts education, and income quite well.
In each of your comments, you have tried to add to what was written. That is neither necessary nor appropriate. Just take what was written for what it specifically addresses. I have no idea what "quite well" means in this context. IQ correlates positively with income at all levels of IQ. The correlation is close to linear and differs between blacks and whites. Above the 40th percentile the mean income for blacks is hither than for whites of the same IQ and that gap increases linearly.
>Education predicts income even better than IQ.
I did not write that. IQ correlates with income, even when education is controlled. Both IQ and education correlate positively with income.
>IQ's prediction of income is not very contingent on
>its correlation with education, though."
See above. There is considerable covariance between IQ and education.
>If that is not your view, please clarify further. If it is
>your view, can you explain how Education is such
>a powerful predictor of income and yet controlling
>for it doesn't much limit IQ's predictive power of
>income?
Both IQ and education correlate positively with income. When education is factored out, there is still a positive correlation between IQ and income. Don't try to restate that which is properly stated.
>Secondly, in regards to g.. I don't think youre
>addressing the point I'm making. g is intended as
>a measure of "general intelligence."
I assume that this means that you have not learned factor analysis. There is no "intention" with respect to g; it is the single factor that emerges at the second (sometimes) or third (usually) order factor in a factor analysis. The term "general intelligence" is a label, not a definition and it can be misleading to those who do not understand g in a mathematical sense.
people like
>yourself observe that g predicts life outcomes and
>from there infer that variance in these outcomes
>must be due primarily to variance in a generalized
>intellectual capability. however, this ignores that g
>correlates with things that are not forms of
>intelligence, and that much of its predictive
>validity may derive from such things.
People who use g with understanding are usually careful to word their comments carefully. There are instances in which the path of causation is fairly obvious and there are some cases where it is not. More often there are multiple paths that are apparent and those can usually be verified. For example, g correlates positively to longevity. That does not say that lifespan is the result of g and I have not seen any researcher make such a claim. Two paths have been proposed and are reasonable with respect to causation. One is the fitness explanation (G. Miller and others) that argues in favor of multiple fitness characteristics being caused by a common factor (not g, but genetic). The other path is related to behavior and has been primarily discussed by Linda Gottfredson. It explains how people manage their personal health care and the probability of them being involved in serious accidents. You can find her papers on this on her web page.
BobW:
The quote you posted said: "the correlation between intelligence and income is not much diminished by partialling out the contributions of education". Contrast this with what you said in your most recent comment: "When education is factored out, there is still a positive correlation between IQ and income. Don't try to restate that which is properly stated."
Note the difference between "not much diminished" and "still a positive correlation". One is a statement of magnitude, the other merely of sign.
It would help if you could post the correlations that you believe are valid..
"People who use g with understanding are usually careful to word their comments carefully. There are instances in which the path of causation is fairly obvious and there are some cases where it is not."
Ok, in the case of income and educational attainment, what is the evidence that cognitive abilities are the main causers? As I stated earlier, even a study which perfectly "partialled out" the effects of education and SES (which I'm yet to find) would still not eliminate all the non-intelligence-related correlates of IQ/g.
"It would help if you could post the correlations that you believe are valid.."
especially the correlation between IQ and income when "partialling out the contributions of education, work experience, marital status, and other demographic variables."
anon,
>On a single measure better than g.
>
>[perform a nonlinear analogue
>of Principal Component Analysis]
How does that undermine "g", or its purported measurability by IQ tests, its predictiveness and heritability and that other evil stuff?
We have a crude definition of "g" as some calculation performed using crude, 19th century, linear, Gaussian, statistics on reference test data (which then operationalizes "g measurement" via IQ tests). We also have crude statistical measures of association between "g" and other crudely measured stuff (correlations). These crude associations appear very substantial and robust across all kinds of studies. Nobody knows any controls that make the apparent effects disappear, for example.
If model mis-specification (The Mismeasure of G) is present, wouldn't it just manifest itself as extra noise relative to whatever nonlinear models better capture reality? In other words, aren't the number and the strength of the associations seen using the admittedly crude methods an indication that "g", or something very much like it, is real and broadly influential regardless of how it's modelled?
Unless there is some hidden bias from the selection of one mathematical technique over another for defining "g" and detecting its relation to other observables, it would be hard to explain away a century of studies by pointing to flawed Gaussian models with their linear MLE estimators.
Post a Comment