I get yelled at from all sides whenever I mention IQ in a post, but I'm a stubborn guy, so here we go again.
Imagine that you would like to communicate something about the
size of an object, using as short a message as possible -- i.e., a single number. What would be a reasonable algorithm to employ? There's obviously no unique answer, and the "best" algorithm depends on the distribution of object types that you are trying to describe. Here's a decent algorithm:
Let rough size S = the radius of the smallest sphere within which the object will fit.
This algorithm allows a perfect reconstruction of the object if it is spherical, but isn't very satisfactory if the object is a javelin or bicycle wheel.
Nevertheless, it would be unreasonable to reject this definition as a single number characterization of
object size, given no additional information about the distribution of object types.
I suggest we think about IQ in a similar way.
Q1: If you had to supply a single number meant to characterize the general cognitive ability of an individual, how would you go about determining that number?
I claim that the algorithm used to define IQ is roughly as defensible for characterizing cognitive ability as the quantity
S, defined above, is for characterizing object size. The next question, which is an empirical one, is
Q2: Does the resulting quantity have any practical use?
In my opinion reasonable people should focus on the second question, that of practical utility, as it is rather obvious that there is no unique or perfect answer to the first question.
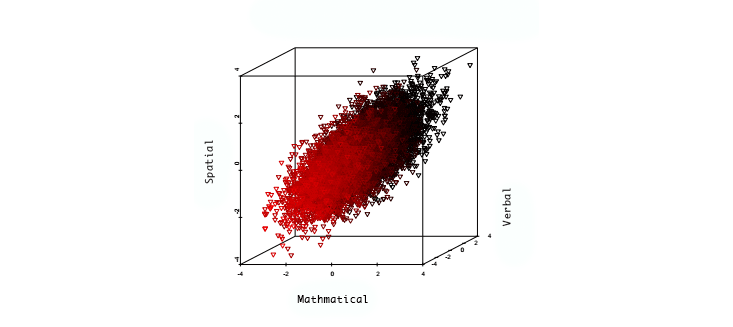
To define IQ, or the general factor g of cognitive ability, we first define some different tests of cognitive ability, i.e., which measure capabilities like memory, verbal ability, spatial ability, pattern recognition, etc. Of course this set of tests is somewhat arbitrary, just as the primitive concept "size of an object" is somewhat arbitrary (is a needle "bigger" than a thimble?). Let's suppose we decide on N different kinds of tests. An individual's score on this battery of tests is an N-vector. Sample from a large population and plot each vector in the N-dimensional space. We might find that the resulting points are concentrated on a submanifold of the N-dimensional space, such that a single variable (which is a special linear combination of the N coordinates) captures most of the variation. As an extreme example, imagine the points form a long thin ellipse with one very long axis; position on this long axis almost completely specifies the N vector. The figure below shows real data, ~100k individuals tested. The principal axis of the ellipsoid is g (roughly speaking; as I've emphasized it is not entire well-defined).
What I've just described geometrically is the case where the N mental abilities display a lot of internal correlation, and have a dominant single factor that arises from
factor analysis.
This dominant factor is what we call g. Note it did not have to be the case that there was a single dominant factor -- the sampled points could have had any shape -- but for the set of generally agreed upon human cognitive abilities, there is.
(What this implies about underlying brain wetware is an interesting question but would take us too far afield. I will mention that g, defined as above using cognitive tests, correlates with neurophysical quantities like reaction time! So it's at least possible that high g has something to do with generally effective brain function -- being wired up efficiently. It's now acknowledged even by hard line egalitarians that g is at least partly heritable, but for the purposes of this discussion we only require a weaker property -- that adult g is relatively stable.)
To summarize, g is the best single number compression of the N vector characterizing an individual's cognitive profile. (This is a lossy compression -- knowing g does not allow exact reconstruction of the N vector.) Of course, the choice of the N tests used to deduce g was at least somewhat arbitrary, and a change in tests results in a different definition of g.
There is no unique or perfect definition of a general factor of intelligence. As I emphasized above, given the nature of the problem it seems unreasonable to criticize the specific construction of g, or to try to be overly precise about the value of g for a particular individual. The important question is Q2: what good is it?
A tremendous amount of research has been conducted on Q2. For a nice summary, see
Why g matters: the complexity of ordinary life by psychologist Linda Gottfredson, or click on the
IQ or
psychometrics label link for this blog. Links and book recommendations
here.
The short answer is that g does indeed correlate with life outcomes. If you want to argue with me about any of this in the comments, please at least first read some of the literature cited above.
From
Gottfredson (WPT =
Wonderlic Personnel Test):
Personnel selection research provides much evidence that intelligence (g) is an important predictor of performance in training and on the job, especially in higher level work. This article provides evidence that g has pervasive utility in work settings because it is essentially the ability to deal with cognitive complexity, in particular, with complex information processing. The more complex a work task, the greater the advantages that higher g confers in performing it well.
... These conclusions concerning training potential, particularly at the lower levels, seem confirmed by the military’s last half century of experience in training many millions of recruits. The military has periodically inducted especially large numbers of “marginal men” (percentiles 10-16, or WPT 10-12), either by necessity (World War II), social experiment (Secretary of Defense Robert McNamara’s Project 100,000 in the late 196Os), or accident (the ASVAB misnorming in the early 1980s). In each case, the military has documented the consequences of doing so (Laurence & Ramsberger, 1991; Sticht et al., 1987; U.S. Department of the Army, 1965).
... all agree that these men were very difficult and costly to train, could not learn certain specialties, and performed at a lower average level once on a job. Many such men had to be sent to newly created special units for remedial training or recycled one or more times through basic or technical training.
Limitations and open questions:
1.
Are there group differences in g? Yes, this is actually uncontroversial. The hard question is whether these observed differences are due to genetic causes.
2.
Is it useful to consider sub-factors? What about, e.g., a 2 or 3-vector compression instead of a scalar quantity? Yes, that's why the SAT has an M and a V section. Some people are strong verbally, but weak mathematically, and vice versa. Some people are really good at visualizing geometric relationships, some aren't, etc.
3.
Does g become less useful in the tail of the distribution? Quite possibly. It's harder and harder to differentiate people in the tail.
4.
How stable is g? Adult g is pretty stable -- I've seen results with .9 correlation or greater for measurements taken a year apart. However, g measured in childhood is nowhere near a perfect predictor of adult g. If someone has a reference with good data on childhood/adult g correlation, please let me know.
5.
Isn't g just the same as class or SES? No. Although there is a weak correlation between g and SES, there are obviously huge variations in g within any particular SES group. Not all rich kids can master calculus, and not all disadvantaged kids read below grade level.
6.
How did you get interested in this subject? In elementary school we had to take the ITED (Iowa Test of Educational Development). This test had many subsections (vocabulary, math, reading, etc.) with 99th percentile ceilings. For some reason the teachers (or was it my parents?) let me see my scores, and I immediately wondered whether performance on different sections was correlated. If you were 99 on the math, what was the probability you were also 99 on the reading? What are the odds of all 99s? This leads immediately to the concept of g, which I learned about by digging around at the university library. I also found all five volumes of the Terman study.
7.
What are some other useful compressed descriptions? It is claimed that one can characterize personality using the
Big Five factors. The results are not as good as for g, I would say, but it's an interesting possibility, and these factors were originally deduced in an information theoretic way. Big Five factors have been shown to be stable and somewhat heritable, although not as heritable as g. Role playing games often use compressed descriptions of individuals (Strength, Dexterity, Intelligence, ...) as do NFL scouts (40 yd dash, veritcal leap, bench press, Wonderlic score, ... ) ;-)
It's a shame that I have to write this post at all. This subject is of such fundamental importance and the results so interesting and clear cut (especially for something from the realm of social science) that everyone should have studied it in school. (Everyone
does take the little tests in school...) It's too bad that political correctness means that I will be subject to abuse for merely discussing these well established scientific results.
Why think about any of this? Here's what I said in response to a comment on
this earlier post:
Intelligence, genius, and achievement are legitimate subjects for serious study. Anyone who hires or fires employees, mentors younger people, trains students, has kids, or even just has an interest in how human civilization evolved and will evolve should probably think about these questions -- using statistics, biography, history, psychological studies, really whatever tools are available.